背景
楼主测试的批量发送信息功能上线之后,后台发现存在少量的ERROR日志,日志内容为手机号码格式不正确。
此前测试过程中没有出现过此类问题,从运营人员拿到的发送列表的TXT,号码是符合规则的,且格式是要求的UTF-8,未发现异常。
因为博主还有别的需求,所以直接反馈给了开发,让开发定位。
定位过程
两天之后,开发给了我两个文件,问我有没有办法找出这两个文件的不同。我看了一下,文件内容完全相同。
后来使用软件beyond compare进行十六进制对比终于发现了区别,
其中一个第一行多了三个字节“EF BB BF”,如下图

原因
多方查证得知是UTF-8有无BOM的区别。
BOM(Byte Order Mark),是UTF编码方案里用于标识编码的标准标记,在UTF-16里本来是FF FE,变成UTF-8就成了EF BB BF。这个标记是可选的,因为UTF8字节没有顺序,所以它可以被用来检测一个字节流是否是UTF-8编码的。微软做这种检测,但有些软件不做这种检测, 而把它当作正常字符处理。
微软在自己的UTF-8格式的文本文件之前加上了EF BB BF三个字节, windows上面的notepad等程序就是根据这三个字节来确定一个文本文件是ASCII的还是UTF-8的, 然而这个只是微软暗自作的标记, 其它平台上并没有对UTF-8文本文件做个这样的标记。
也 就是说一个UTF-8文件可能有BOM,也可能没有BOM
解决方法
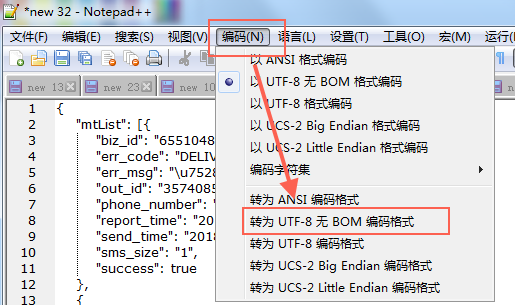
使用Notepad++编辑,转换为UTF-8无BOM格式即可
参考资料: